HOSTED·AI PLATFORM
Turnkey solution for high-margin GPU cloud
Sell multi-tenant GPUaaS for AI model training · tuning · inference
Designed for service providers, hosted•ai brings true multi-tenancy to GPUaaS, delivering 5x more profit per card vs. GPU passthrough
Complete AI hosting + GPU cloud stack

Deploys to bare metal in 24h
Software-defined GPU, CPU, storage, network
Orchestration + monetization tools
GPU multi-tenancy for maximum utilization
GPU overcommit for maximum margins
AI model / application library
Rebrandable self-service UI
Ask for a demo!






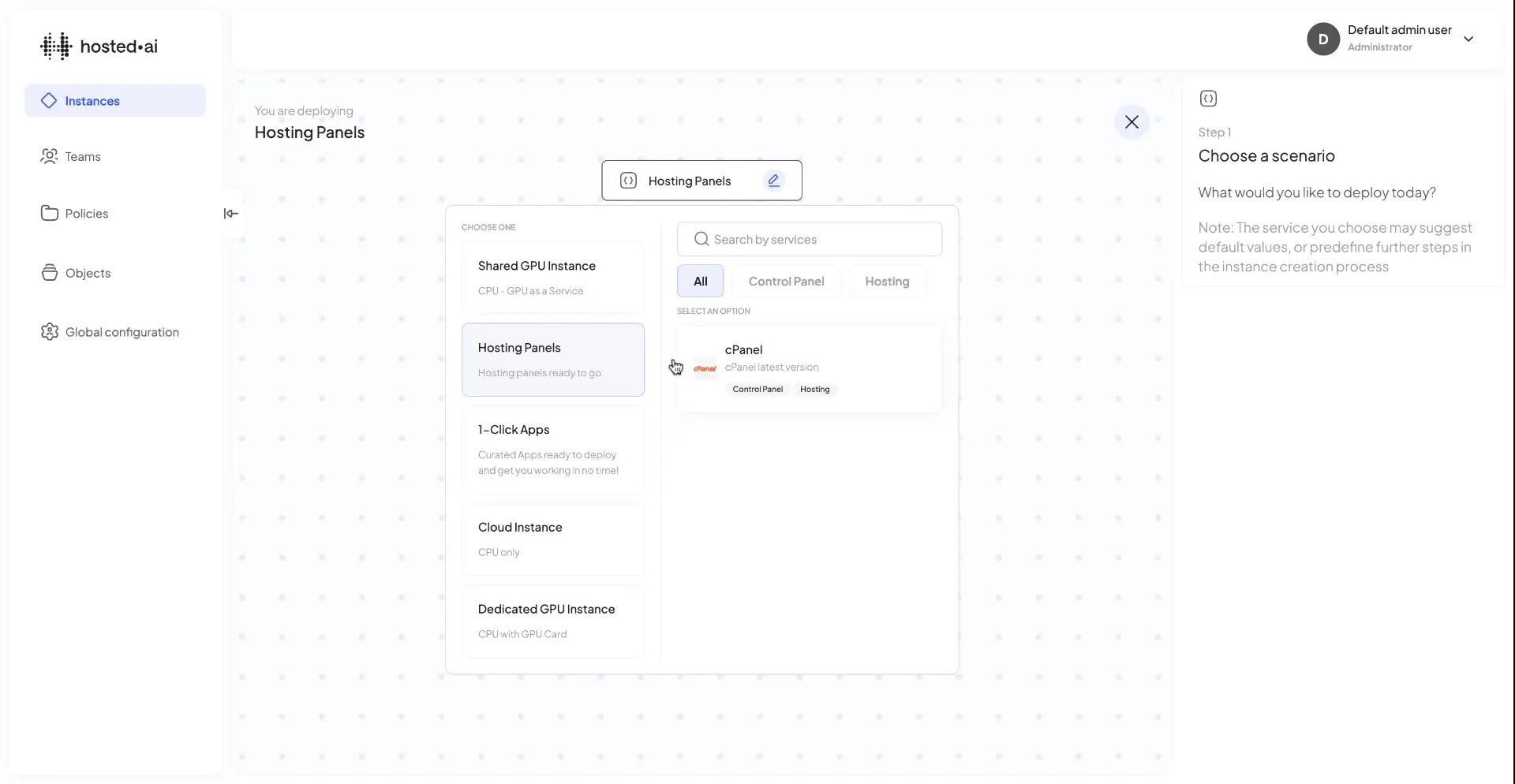
One-click AI models and apps
With AI model library integration, Ansible playbooks and Bring Your Own Model, your customers can deploy AI instances in seconds.

Software-Defined GPU
Sell GPUaaS with the same dynamic resource allocation, autoscaling and hardware utilization (overcommit) as traditional hosting or cloud.
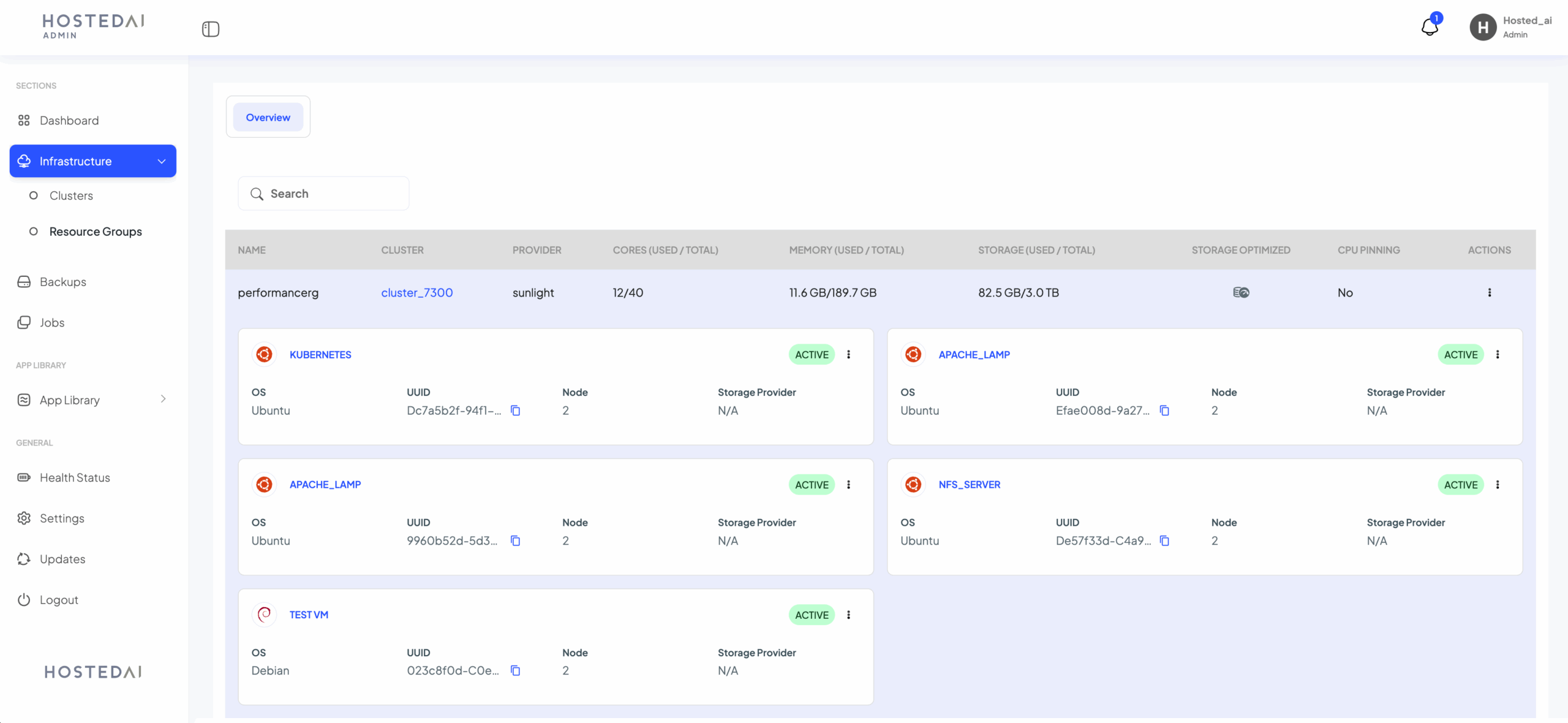
GPU pooling
Assign GPUs in a cluster to pools. Configure pricing, access and sharing policies to suit different customers & workloads.
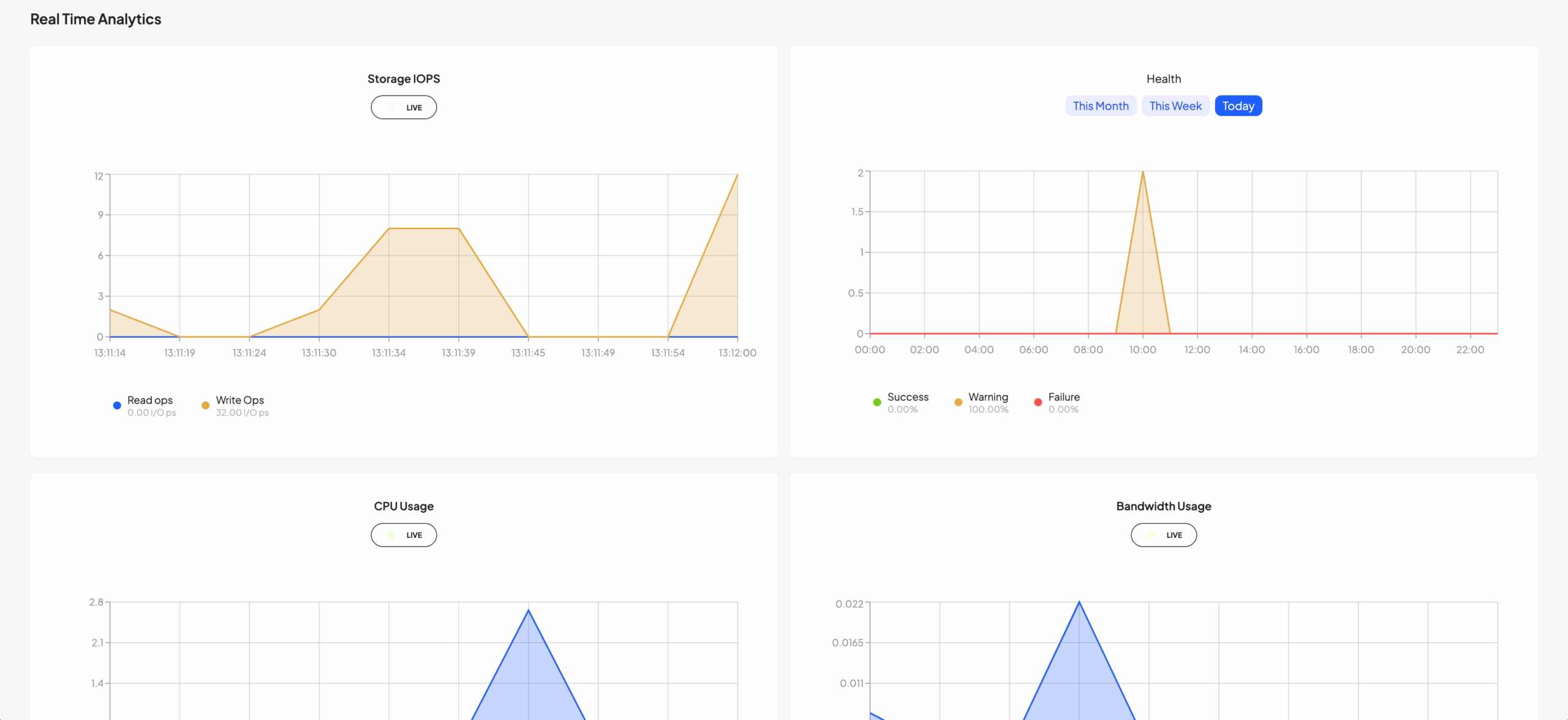
100% GPU utilization
hosted•ai distributes workloads to GPU pools dynamically, to maximize utilization of each card.
PAYG GPUaaS
Bill users for the GPU VRAM/TFLOPs consumed, as well as billing for fixed resources or cards.
GPUaaS overcommit
Configure share ratios to enable GPU overselling, and increase margins 5x or more.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Secure multi-tenant GPUaaS
hosted·ai brings full multi-tenancy to GPUs. Serve more customers with less investment in GPU infrastructure, and change the cost/margin equation for GPU cloud.
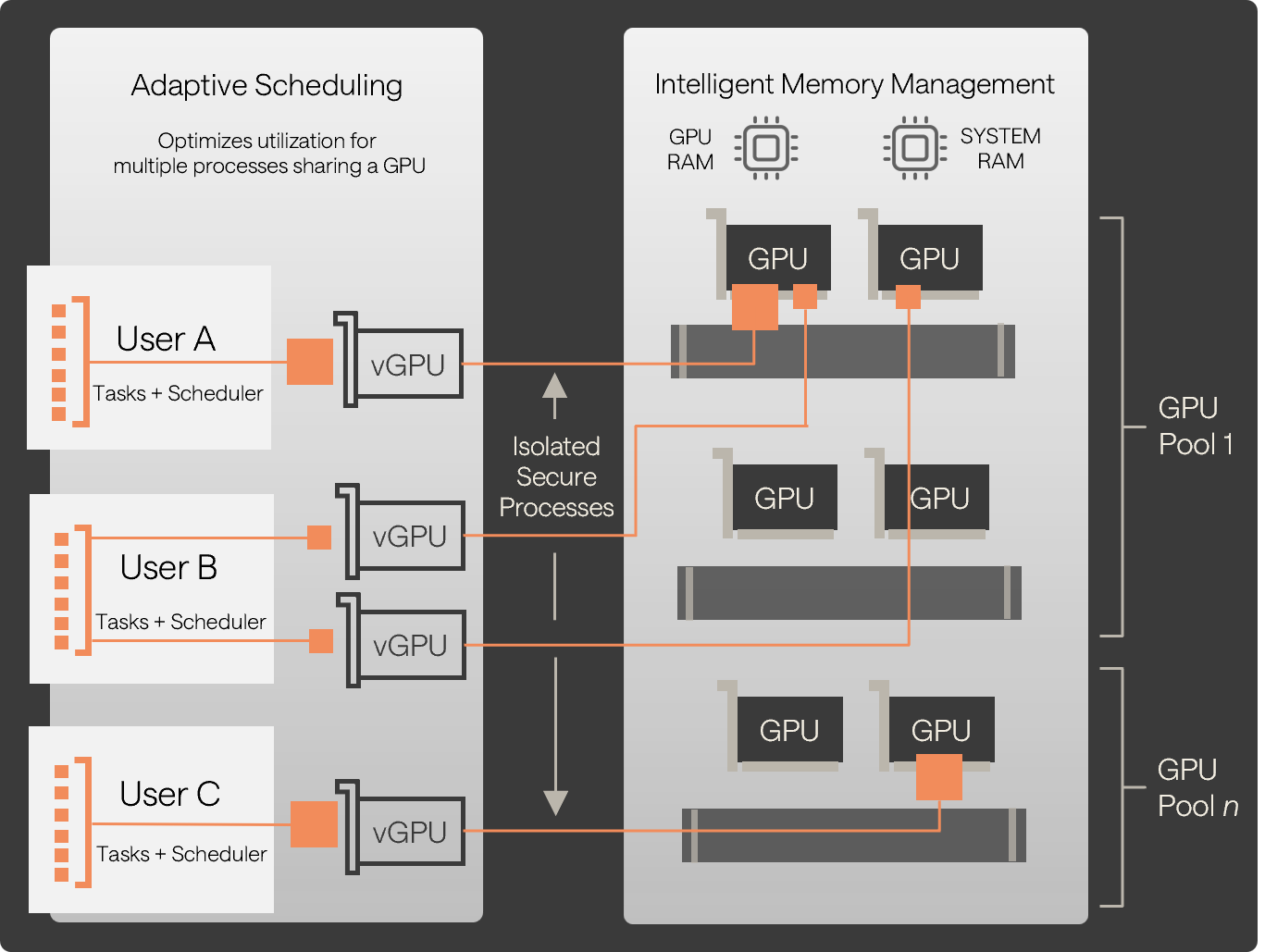
Isolated GPU sharing
Many users run workloads across a pool of GPUs at the same time. User tasks are isolated and secured from other users.
Transparent to users
Users see one or more virtual GPUs, even when their tasks execute on the same physical GPU as other user tasks.
Elastic GPU resources
Instead of allocating entire GPUs or instances to users, GPU resources (TFLOPS/VRAM) can be allocated to users from GPU pools.
Dynamic scheduling
Adaptive scheduling optimizes utilization for multiple processes sharing a GPU. Users pay for the GPU resources they consume.
Monetization
Flexible pricing and packaging policies make it easy to bill for your hosted•ai cloud.
GPU
Bill users for the GPU VRAM/TFLOPs consumed, as well as billing for fixed resources or cards
CPU, storage, network
Bill for vCPU cores, storage capacity, bandwidth
Packages
Combine resources into easy-to-consume packages (CPU, GPU, storage, network)
Applications
Combine applications with resources and bill for one-click installs
Regions
Set global or local prices for different datacenter locations
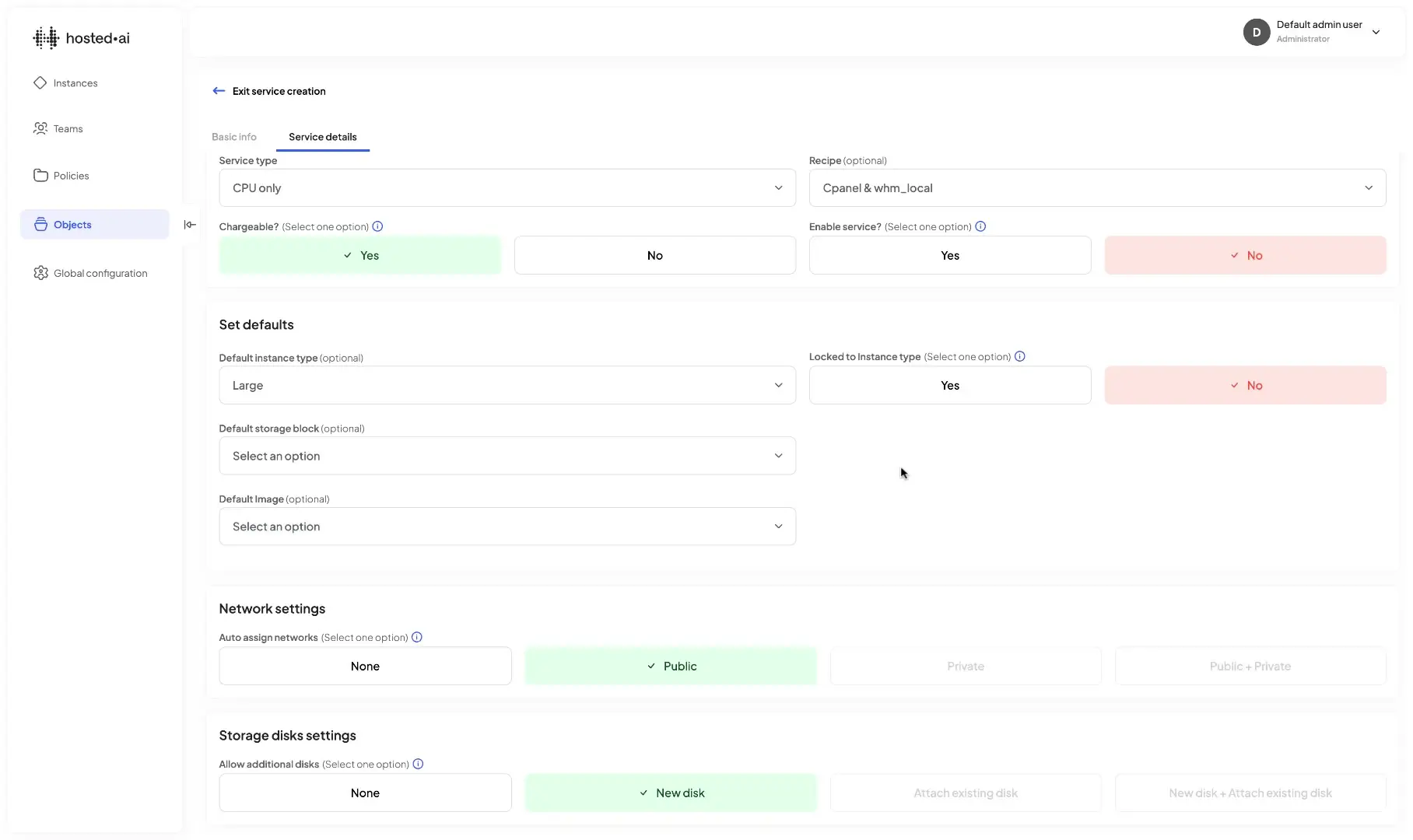
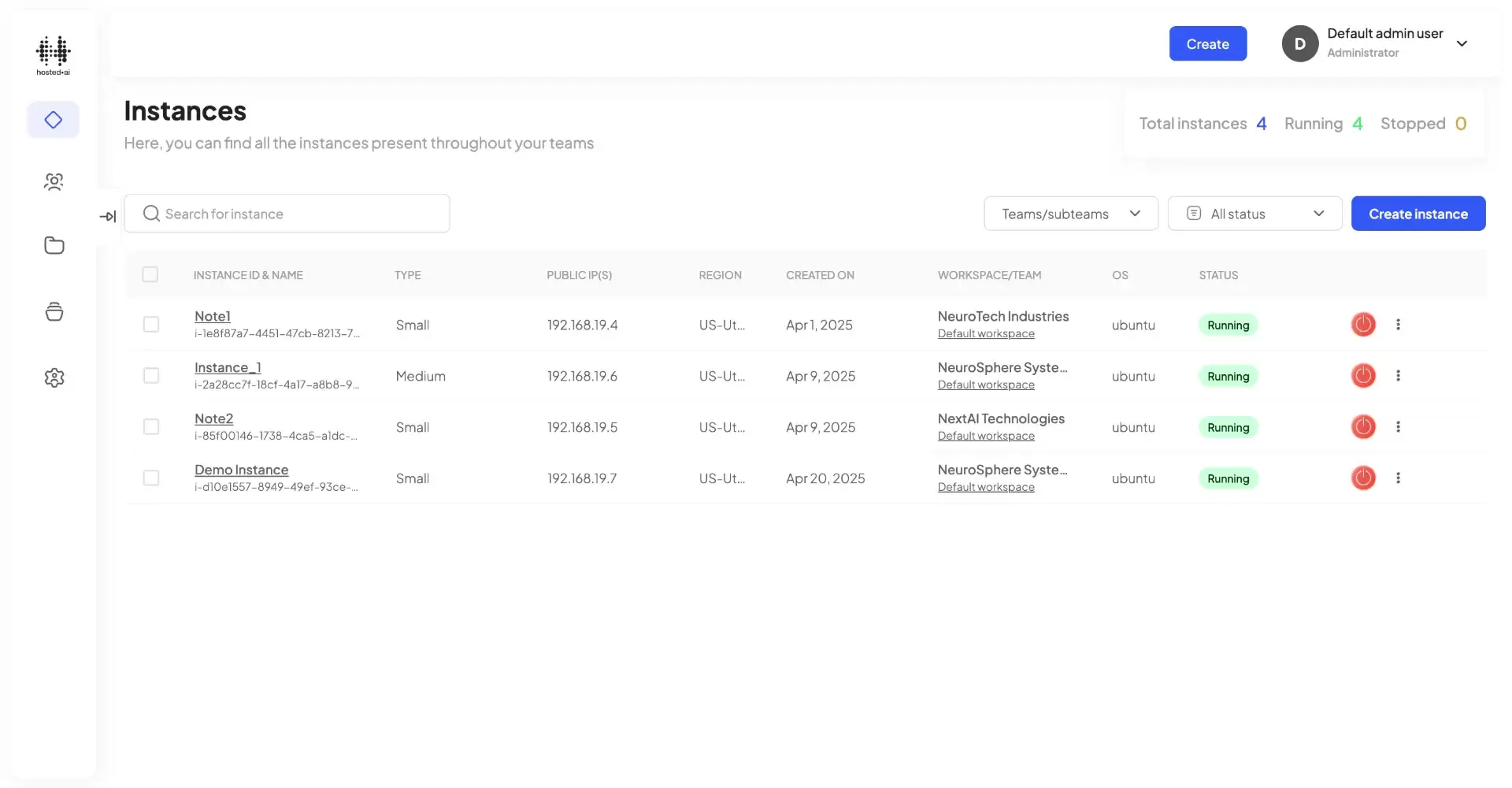
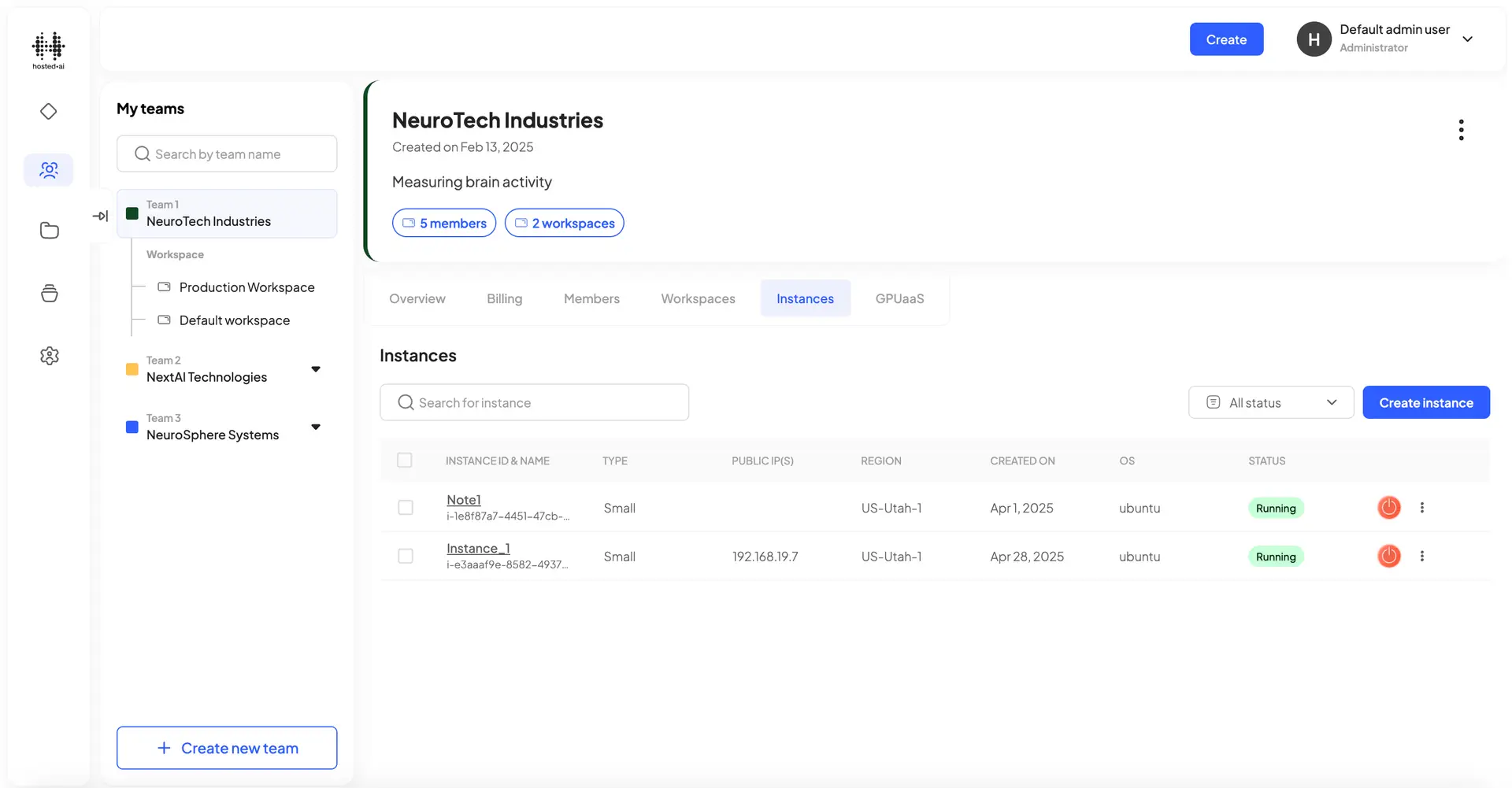
Team + quota management
It’s easy to sell GPUaaS in a way that fits with customer processes and workflows.
Resource pools are allocated to customer teams – teams have their own workspaces, users and permissions/limits
For example, a team might consist of an admin and different developers, each with their own rights and access to resources
Integrations
hosted•ai has a full REST API and integrates with a growing range of service provider billing and customer management systems, including WHMCS
Flexible deployment
hosted•ai can be deployed as a full stack solution for VMs and GPU/GPUaaS, or as a virtualized GPU cloud solution using bare metal or cloud-based GPUaaS nodes